2026年4月,中科院计算所自然语言处理组5篇论文被ACL 2026会议接收,其中1篇论文被ACL主会录用,4篇被Findings of ACL录用。ACL的全称是The Association for Computational Linguistics,是国际计算语言学界影响力最大的学术组织。ACL年度会议也是计算语言学领域的最重要的国际会议,是CCF推荐的计算语言学方面唯一的A类会议。Findings of ACL是从ACL 2021开始引入的在线附属出版物。
被录用的论文简介如下:
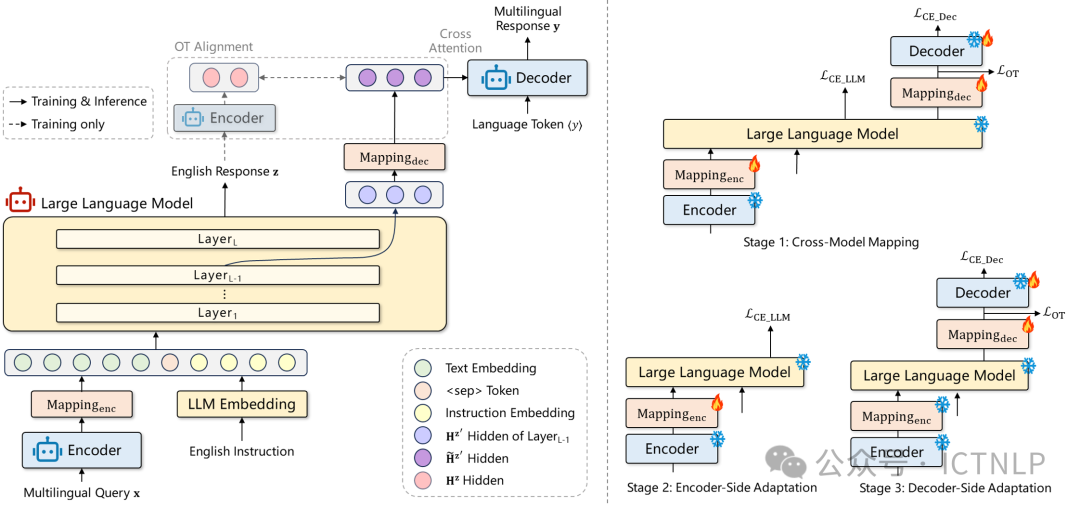
1. Language on Demand, Knowledge at Core: Composing LLMs with Encoder-Decoder Translation Models for Extensible Multilinguality
作者:卜梦煜,冯洋*
Accepted by ACL 2026 Main Conference
简介:尽管大语言模型(LLM)具备很强的通用能力,但很大程度上局限于高资源语言,多语言性能依然极不均衡。我们认为 LLM 并非缺少相关知识,而是难以在低资源语言稳定调用。由此出发,我们提出了一种新的多语言扩展范式 XBridge:组合 LLM 以英文为中心的通用能力,以及现有多语言机器翻译(NMT)模型的多语言理解和生成能力,实现二者的能力互补,组合成一个多语言通用模型。即将多语言理解和生成卸载到外部 NMT 模型,LLM 进行以英文为中心的通用知识处理。实验表明,XBridge 能够将 LLM 的低资源语言甚至未见语言的理解和生成能力提升到接近外部 NMT 模型的水平,显著缩小高资源、低资源语言间性能差距,在下游任务上保持或提升高资源语言能力,全程无需训练 LLM。Paper: https://arxiv.org/abs/2603.17512Code: https://github.com/ictnlp/XBridge
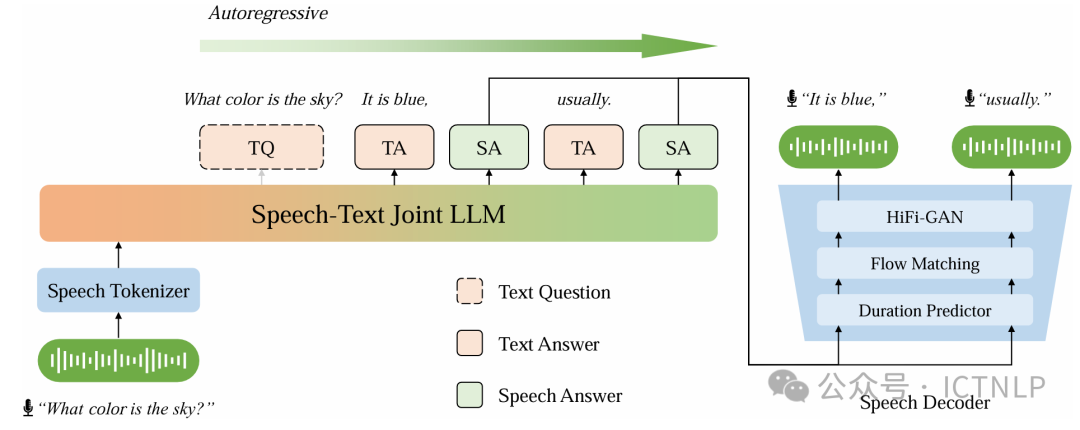
2. Efficient Training for Cross-lingual Speech Language Models
作者:周䶮,房庆凯,洪运,冯洋*
Accepted by Findings of ACL 2026
简介:我们提出了一种面向跨语言语音大模型的高效训练方法,并用该方法构建了跨语言语音大模型 CSLM 。在预训练阶段,该方法基于离散语音词元使文本大模型支持语音输入输出,通过引入新颖的对齐策略进行持续预训练,有效实现了跨模态和跨语种的同时对齐 。在指令微调阶段,我们提出了一种语音-文本交替的模态链(speech-text interleaved chain-of-modality)生成过程,在加速生成的同时进一步对齐语音文本模态。实验表明,CSLM 无需依赖海量语音数据即可实现不同模态与语言的同步对齐,展现出较好的语言可扩展性,并在跨模态、单语种和跨语种的对话任务中均取得了优异的表现 。
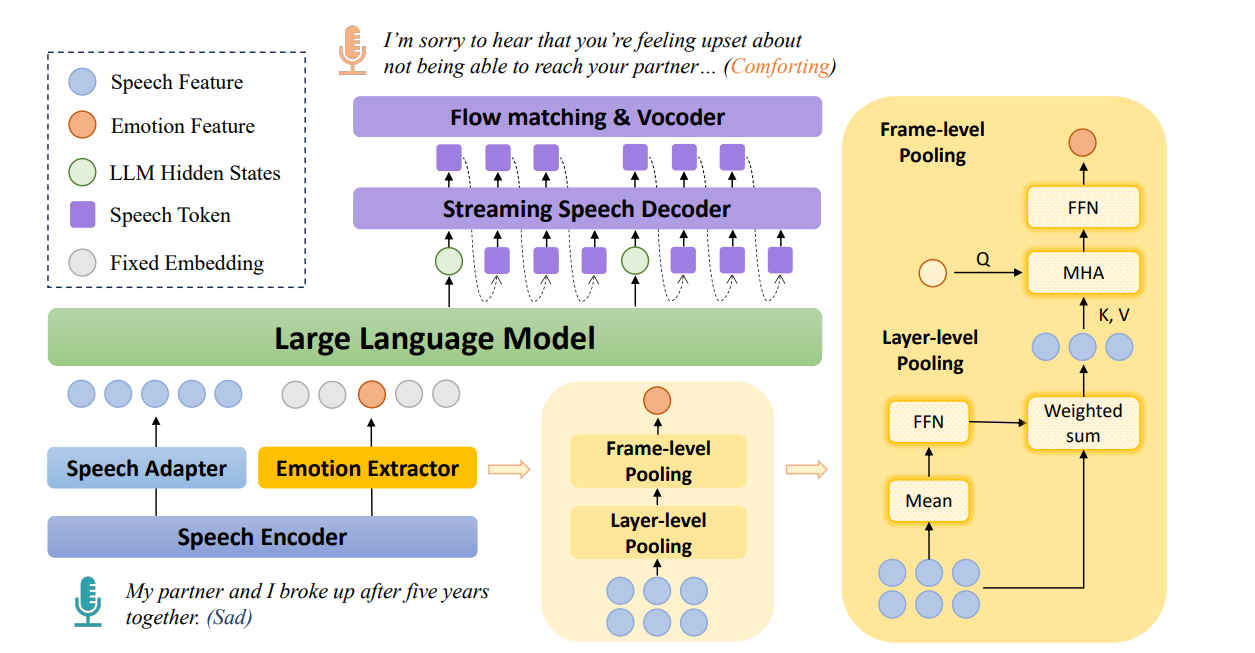
3. FreezeEmpath: Efficiently Training an Empathetic Spoken Chatbot with Frozen LLM
作者:洪运,周䶮,冯洋*
Accepted by Findings of ACL 2026
简介:共情能力对于口语对话系统至关重要,它使机器能够识别人类语音的情感语调并做出富有同理心的回应。近年来,基于大语言模型(LLM)开发共情口语对话系统的研究取得了显著进展。然而,在训练此类模型时,仍然存在诸多挑战,其中最显著的挑战在于对人工构造的共情语音指令数据的依赖。构造这类数据需要复杂且精细的流程,成本较高且难以大规模扩展。使用跨模态的共情语音指令数据对大模型进行微调也可能会导致灾难性遗忘,削弱其通用能力。除此之外,现有的共情语音大模型也存在隐式共情能力较差,生成的语音缺乏情感表现力等问题。针对这些问题,我们提出了FreezeEmpath,一个端到端的共情语音大模型。FreezeEmpath的训练过程依赖于LLM的内生共情能力,只需要使用现有的中性语音指令和SER数据,不需要精心构造的共情语音指令数据,并保持基座LLM的参数冻结。实验结果表明,FreezeEmpath能够生成富有情感表现力的语音,并在共情对话、语音情绪识别和口语问答任务中取得了优秀的表现,证明了我们训练策略的高效性。
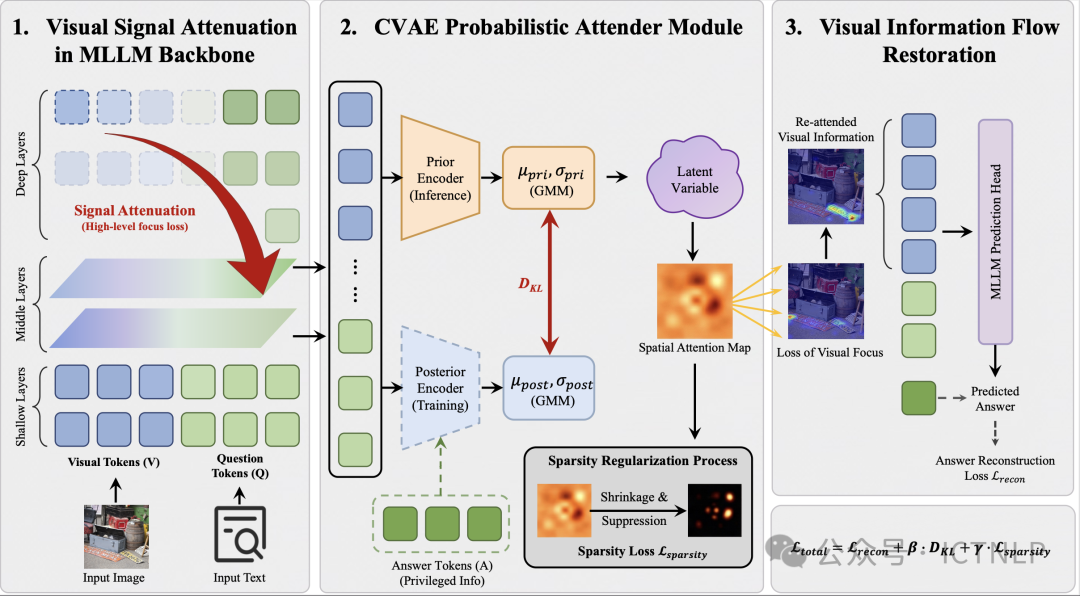
4. From Attenuation to Attention: Variational Information Flow Manipulation for Fine-Grained Visual Perception
作者:朱纪龙,冯洋*
Accepted by Findings of ACL 2026
简介:我们提出了一种面向多模态大模型细粒度视觉感知的变分信息流操控框架 VIF。我们从多模态大模型内部的信息传递过程出发,发现在现有 MLLM 的深层推理过程中,视觉信号会被文本 token 逐步压制和稀释,出现视觉衰减现象,从而难以持续关注小目标、局部细节和细微关系。为此,VIF 以概率建模的方式,将与问答任务相关的视觉显著性表示为潜变量分布,并通过基于 CVAE 的可插拔模块,在训练时借助答案信息学习任务相关的视觉关注,在推理时凭借图像和问题重建这种关注,并将其注入深层信息流中,从而把模型从“看不清、看不准”转变为对关键视觉区域的主动聚焦,在通用视觉理解、细粒度感知和视觉 grounding 等任务上都带来稳定提升。
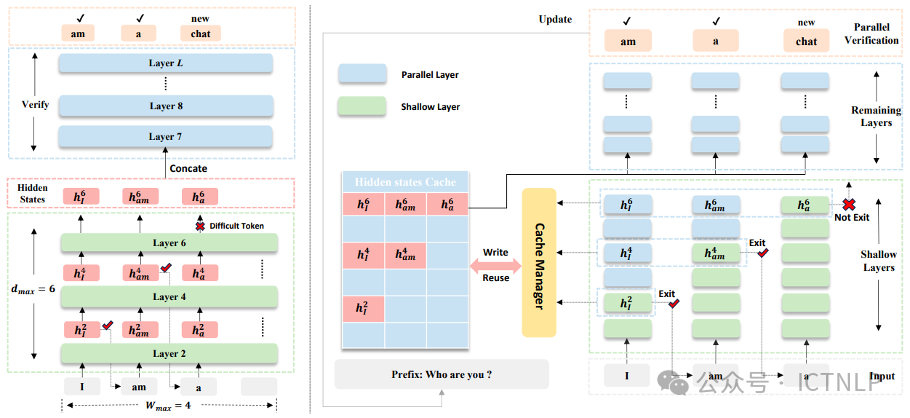
5. SpecBound: Adaptive Bounded Self-Speculation with Layer-wiseConfidence Calibration
作者:温卓凡,冯洋*
Accepted by Findings of ACL 2026
简介:投机解码(Speculative Decoding)已成为加速大语言模型(LLM)自回归推理的一种极具前景的方法,尤其适用于逻辑推理与智能体协同等长文本生成场景。自推测(Self-draft)方法直接利用基座模型自身进行token预测,虽免去了维护独立辅助模型的开销,但仍面临两大关键瓶颈:其一,浅层网络常产生置信度虚高但结果错误的token预测;其二,草稿序列中一旦出现难以预测的token,便会迫使整个序列进入深层网络进行冗余计算,从而严重削弱候选词接受率与整体加速效果。针对上述问题,我们提出了一种全新的自推测框架。该方法引入基于层深的平滑策略动态校准提前退出(early-exit)置信度,并依据每一token的解码难度自适应地限制推测长度。当达到推测边界时,框架会将候选词隐状态在深层网络中进行统一的并行验证。该机制在最大化计算效率的同时,确保了输出结果与原始模型严格等价。该方法全程无需修改基座LLM的任何参数,在多种模型架构与多样化的长文本生成任务上,相比标准自回归解码最高可实现2.33× 的端到端加速。