2024年9月,计算所NLP团队LLM推理加速工作被NeurIPS 2024会议接收。NeurIPS的全称是Thirty-eighth Conference on Neural Information Processing Systems,是机器学习领域的顶级会议之一。NeurIPS 2024将于2024年12月9日-15日在加拿大温哥华召开。
被录用论文的简要介绍如下:
- Speculative Decoding with CTC-based Draft Model for LLM Inference Acceleration. (Zhuofan Wen, Shangtong Gui, Yang Feng)
- NeurIPS, poster
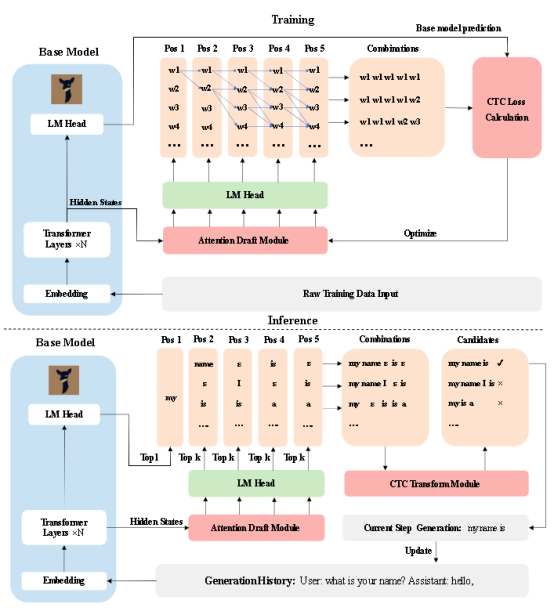
作为一种高效的的推理加速技术,投机解码逐渐受到广泛关注。投机解码通常训练参数量更小的辅助模型在每一解码步骤生成候选词序列,由大规模语言模型进行验证,挑选最佳候选序列作为本轮解码结果。通过单轮解码多词实现加速。在这个框架中,最终的推理提速效果主要由辅助模型的解码速度以及所提供候选词序列的接受率共同决定。目前广泛使用的辅助模型通常以非自回归的方式生成候选词序列,忽略了不同候选词间的上下文关系。因此,尽管这种策略具有较快的解码速度,但候选词的接受率并不理想。本工作聚焦于提高辅助模型的预测性能,旨在通过提高候选词接受率实现更理想的推理加速比。基于CTC算法,我们提出了的CTC-drafter辅助模型加速框架。在训练阶段,通过融入CTC损失函数,基于动态规划遍历所有可能序列,强化上下文信息,从而实现更高质量的候选序列生成。实验结果表明,与基线模型相比,CTC-drafter可以实现更高的候选词接受率,从而实现更理想的推理加速比。
(英文版摘要)
Inference acceleration of large language models (LLMs) has been put forward in many application scenarios and speculative decoding has shown its advantage in addressing inference acceleration. Speculative decoding usually introduces a draft model to assist the base LLM where the draft model produces drafts and the base LLM verifies the draft for acceptance or rejection. In this framework, the final inference speed is decided by the decoding speed of the draft model and the acceptance rate of the draft provided by the draft model. Currently the widely used draft models usually generate draft tokens for the next several positions in a non-autoregressive way without considering the correlations between draft tokens. Therefore, it has a high decoding speed but an unsatisfactory acceptance rate. In this paper, we focus on how to improve the performance of the draft model and aim to accelerate inference via a high acceptance rate. To this end, we propose a CTC-based draft model which strengthens the correlations between draft tokens during the draft phase, thereby generating higher-quality draft candidate sequences. Experiment results show that compared to strong baselines, the proposed method can achieve a higher acceptance rate and hence a faster inference speed.