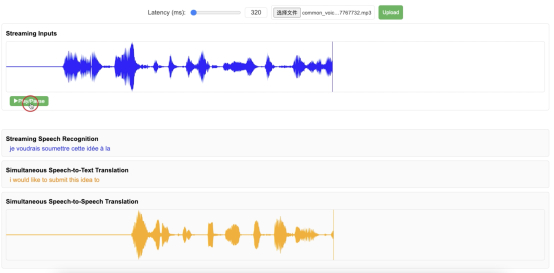
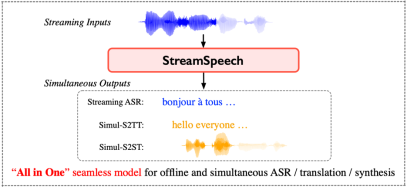
2024年6月,中国科学院计算技术研究所自然语言处理团队发布“All in One”流式语音模型——StreamSpeech。该模型可以在用户说话的同时,以端到端的方式实现语音识别、语音翻译、语音合成的多任务实时处理,延时低至320毫秒。StreamSpeech是能够以端到端方式同时完成多项离线和流式语音任务的开源模型。StreamSpeech可以部署在手机、耳机、AR眼镜等设备,助力国际会议、跨国旅行等场景下的低延时跨语言交流需求。
StreamSpeech的论文、代码、模型、Demo均已开源:

论文:https://aclanthology.org/2024.acl-long.485.pdf
代码:https://github.com/ictnlp/StreamSpeech
模型:https://huggingface.co/ICTNLP/StreamSpeech_Models
Demo:https://ictnlp.github.io/StreamSpeech-site/
StreamSpeech采用先进的two-pass架构,集成了流式语音编码器、实时文本解码器和同步的文本到语音合成模块。通过引入连接时序分类(Connectionist temporal classification,CTC)对齐机制,StreamSpeech能够控制模型在用户说话的同时理解并生成语音识别、翻译和合成结果。StreamSpeech在离线和实时语音到语音翻译上超过Meta的UnitY架构,在开源数据集上取得当前的最佳性能。此外,StreamSpeech还能在翻译过程中生成中间文本结果,为用户提供“边听边看”的流畅体验。
StreamSpeech提供了本地部署的Demo视频(https://github.com/ictnlp/StreamSpeech),欢迎体验: