2025年1月,自然语言处理组2篇论文被ICLR 2025接收。ICLR 2025的全称是the 13th International Conference on Learning Representations. ICLR, ICML和NeurIPS是三大机器学习和人工智能会议,在相关领域有较大的影响力和关注度。ICLR 2025将于2025年4月24日-4月28日在新加坡举行。
被录用论文的简要介绍如下:
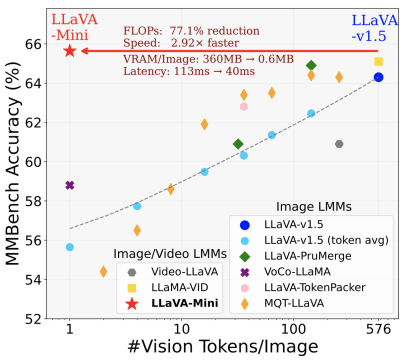
- LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token (Shaolei Zhang, Qingkai Fang, Zhe Yang, Yang Feng)
简介:GPT-4o等实时多模态大模型(LMM)的出现引发了人们对高效LMM的关注。LMM框架通常将视觉输入编码为视觉token(连续表示),并将它们和文本指令集成到大型语言模型(LLM)的上下文中,其中大规模参数和大量上下文token(主要是视觉token)会导致大量的计算开销。以往的工作总是集中在用较小的模型替换LLM基座,而忽视了token数量这一关键问题。在本文中,我们介绍了高效多模态大模型——LLaVA-Mini,该模型能够在统一架构下高效地处理并理解普通图像、高分辨率图像和长视频。得益于多模态大模型的可解释性,LLaVA-Mini对视觉信息进行了有效压缩,每张图像仅需一个视觉token进行表示。在保证视觉理解性能的基础上,LLaVA-Mini显著提升了图像和视频理解的效率,具体表现为:减少计算量(FLOPs降低77%)、缩短响应时延(每张图像处理仅需40毫秒)、显著降低显存占用(从每张图像360MB降至0.6MB,支持在24GB GPU上处理长达3小时的视频)。
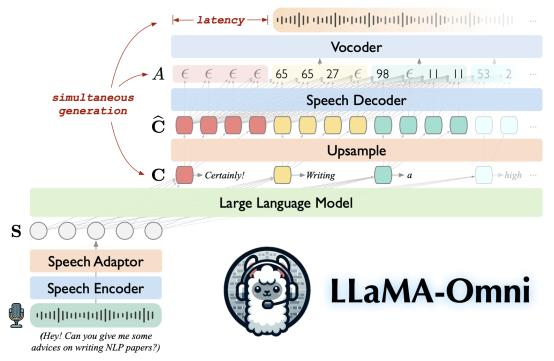
- LLaMA-Omni: Seamless Speech Interaction with Large Language Models (Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, Yang Feng)
简介:GPT-4o等闭源大模型能够通过语音与大语言模型(LLM)进行实时交互,与传统的基于文本的交互相比,显著增强了用户体验。然而,对于如何基于开源LLM构建语音交互模型,仍然缺乏探索。因此,我们提出端到端语音交互大模型——LLaMA-Omni,该模型可以像GPT-4o以极低延时与用户进行语音交互。LLaMA-Omni基于最新的Llama-3.1-8B-Instruct开发,面向通用指令遵循任务,能够根据语音指令同步生成语音与文本回复,回复内容和风格均显著优于现有开源语音大模型。同时,LLaMA-Omni的响应延时可低至236ms,低于GPT-4o的平均延时320ms。LLaMA-Omni由语音编码器、语音适配器、LLM和流式语音解码器组成,用户的语音指令由语音编码器进行编码,经过语音适配器后输入LLM。LLM直接基于语音指令生成文本回复,与此同时,语音解码器同步生成对应的语音回复,为用户提供低延迟、高质量的语音交互。此外,LLaMA-Omni仅需在4张GPU上训练3天时间,显著降低了语音大模型训练所需的计算资源。