2024年12月3日,中国科学院计算技术研究所自然语言处理团队发布通用大语言模型“百聆2“,相关论文同步在Arxiv上发表。该工作通过语言对齐高效地将知识和生成能力从高资源语言迁移到低资源语言,增强了大语言模型的多语言能力。目前团队已开源模型权重及代码,并在中科南京信息高铁研究院的支持下完成了“百聆2”的线上部署。欢迎大家了解及试用!
该研究工作简要介绍如下:
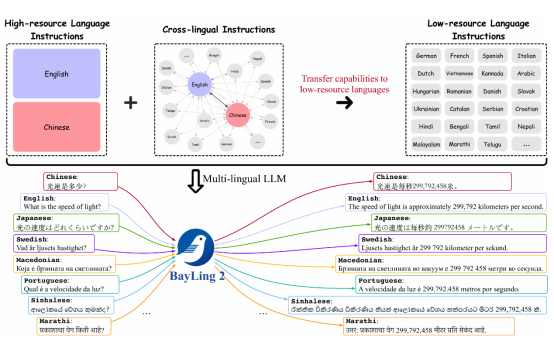
大型语言模型具有丰富的知识和强大的生成能力,能够赋能人们生活的方方面面。然而,这些知识和能力主要集中在高资源语言中,低资源语言的知识相对有限且生成能力仍然较弱。因此,增强大语言模型的多语言能力对服务全球100多个语言社群至关重要的。对于增强多语言能力,直接的方法是构建各种语言的指令数据,然而构建100多种语言的指令数据却要耗费很高的成本。
为此,研究团队研发了百聆2,通过语言对齐高效地将生成能力和知识从高资源语言迁移到低资源语言。为实现这一目标,研究团队构建了一个包含320万条指令的数据集,其中包括高资源语言(中文和英文)指令以及适用于100多种语言的跨语言指令,以便在不同语言之间实现能力迁移。基于Llama 2和Llama 3基座模型,研究团队开发了百聆-2-7B、百聆-2-13B和百聆-2-8B模型,并对百聆 2进行了全面的评估。在涵盖100多个语言的多语言翻译任务上,百聆 2比同规模的开源模型拥有更好的性能;在多语言知识与理解基准测试中,百聆 2在超过20种低资源语言上取得了显著改进,表明了其具有优越的从高资源语言向低资源语言的知识迁移能力;此外,在英语基准测试中的结果表明,百聆 2在高资源语言上仍然保持了高水准,同时提高了在低资源语言上的性能。
试用入口:https://nlp.ict.ac.cn/bayling/demo/
项目首页:http://nlp.ict.ac.cn/bayling
论文链接:https://arxiv.org/pdf/2411.16300
代码仓库:https://github.com/ictnlp/BayLing
模型权重:
百聆-2-7B :https://huggingface.co/ICTNLP/bayling-2-7b
百聆-2-13B:https://huggingface.co/ICTNLP/bayling-2-13b
百聆-2-8B :https://huggingface.co/ICTNLP/bayling-2-llama-3-8b
百聆仍在持续优化中,如果大家有任何建议,欢迎联系bayling@ict.ac.cn。感谢大家的支持!
开始探索百聆请点击链接:https://nlp.ict.ac.cn/bayling/demo/