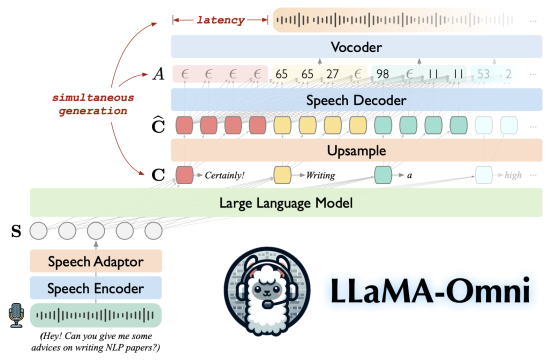
2024年9月,中国科学院计算技术研究所自然语言处理团队发布端到端语音交互大模型——LLaMA-Omni,可以像GPT-4o以极低延时与用户进行语音交互。LLaMA-Omni基于最新的Llama-3.1-8B-Instruct开发,面向通用指令遵循任务,能够根据语音指令同步生成语音与文本回复,回复内容和风格均显著优于现有开源语音大模型。同时,LLaMA-Omni的响应延时可低至226ms,低于GPT-4o的平均延时320ms。

LLaMA-Omni的论文、代码、模型均已开源:
论文:https://arxiv.org/abs/2409.06666
代码:https://github.com/ictnlp/LLaMA-Omni
模型:https://huggingface.co/ICTNLP/Llama-3.1-8B-Omni

LLaMA-Omni由语音编码器、语音适配器、LLM和流式语音解码器组成,用户的语音指令由语音编码器进行编码,经过语音适配器后输入LLM。LLM直接基于语音指令生成文本回复,与此同时,语音解码器同步生成对应的语音回复,为用户提供低延迟、高质量的语音交互。此外,LLaMA-Omni仅需在4张GPU上训练3天时间,显著降低了语音大模型训练所需的计算资源。