课题组今年有3篇论文被EMNLP 2021接收, 其中1篇论文被EMNLP主会录用,2篇被findings of EMNLP录用。EMNLP全称是Empirical Methods in Natural Language Processing,是自然语言处理领域国际顶级会议之一;Findings of EMNLP是EMNLP 2020引入的在线附属出版物。
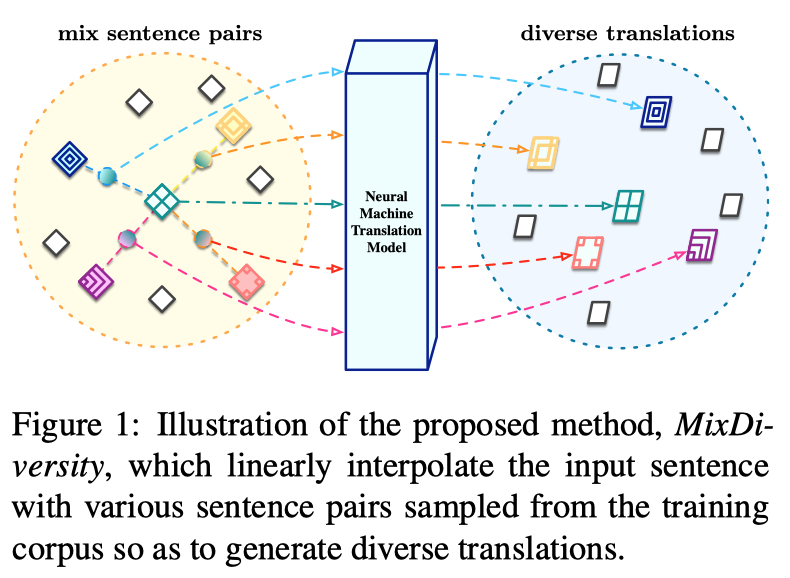
Universal Simultaneous Machine Translation with Mixture-of-Experts Wait-k Policy (Shaolei Zhang, Yang Feng)
Main Conference, Long Paper
同步机器翻译 (Simultaneous Machine Translation, SiMT) 在阅读整个源句子之前开始翻译,因此它的性能由翻译质量和延迟来评估。 同步机器翻译在不同的场景下有不同的延时需求,为了满足不同翻译质量和延迟的要求,以前的方法通常需要训练多个不同的SiMT模型,导致计算成本很高。 在本文中,我们提出了一种基于多专家Wait-k 策略(Mixture-of-Experts Wait-k policy)的通用 SiMT 模型,以动态地引入不同的训练延迟。具体来说,multi-head attention中的多个注意力头被视为一系列wait-k专家,并被分配不同的训练延迟。对于不同的测试延迟和输入的源端句子,模型动态地调整每个专家的权重以产生正确的翻译。 在三个数据集上的实验表明,我们的方法可以在不同延迟下优于所有强基线,包括最先进的自适应策略。
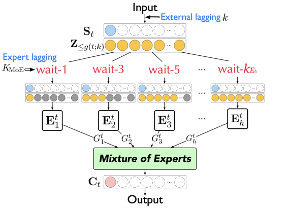
Modeling Concentrated Cross-Attention for Neural Machine Translation with Gaussian Mixture Model (Shaolei Zhang, Yang Feng)
Findings of EMNLP, Long Paper
交叉注意力(cross-attention)是神经机器翻译的重要组成部分,在以前的方法中总是通过点积注意力来实现的。然而,点积注意力只考虑词之间的成对相关性,导致其在处理长句时容易出现分散和忽略源相邻关系等问题。受语言学的启发,我们认为上述问题是由于基于点积注意力的计算方式忽略了一种称为集中注意力(concentrated attention)的交叉注意力。这种集中的交叉注意力首先集中在几个中心词上,然后在它们周围传播扩散。 在这项工作中,我们应用高斯混合模型(Gaussian Mixture Model,GMM)来建模交叉注意力中的集中注意力。 我们在三个数据集上进行的实验和分析表明,所提出的方法优于基线,并且在对齐质量、N-gram 准确性和长句翻译方面都有显着提高。
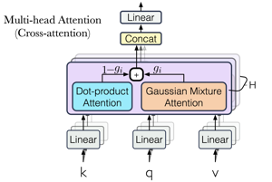
Mixup Decoding for Diverse Machine Translation (Jicheng Li,Pengzhi Gao,Xuanfu Wu,Yang Feng,Zhongjun He,Hua Wu, Haifeng Wang)
Findings of EMNLP, Short Paper
本文提出了一个基于Mixup的翻译多样性增强方法,该方法在语义空间中对源端句子进行混合采样以获取不同的源端输入,进而生成不同的目标端译文。相比于已有的翻译多样性方法,我们所提出的方法在生成多样性更强的译文的同时,无需对模型结构进行修改,因而不会带来额外的训练开销。