Congratulations to NLP group for having five papers accepted by ACL 2023, including 4 papers by the main conference and 1 paper by Findings of ACL! ACL stands for The Association for Computational Linguistics, which is the most influential academic organization in the international computational linguistics community. The annual ACL conference is also the most important international conference in the field of computational linguistics and the only CCF-A conference in the field of computational linguistics. The main conference papers of ACL will be published in Proceedings of ACL, while Findings of ACL is an online affiliated publication introduced since ACL 2021. ACL 2023 will be held in Toronto, Canada from July 9 to July 14, 2023.
The accepted papers are summarized as follows:
- Understanding and Bridging the Modality Gap for Speech Translation (Qingkai Fang, Yang Feng) .
- Accepted by ACL 2023 Main Conference. Long Paper.
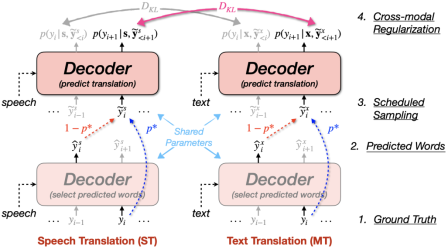
Abstract: Speech translation (ST) translates input speech directly into text in another language, effectively reducing the communication barrier between people of different languages. Due to the scarcity of ST corpus and the difficulty of learning the mapping from source speech to target text, researchers usually introduce the machine translation (MT) task to assist ST training. However, due to the modality gap between speech and text, the performance of ST usually lags behind MT. In this paper, we first measure the significance of the modality gap based on the decoder representation differences, and we find that (1) the exposure bias problem causes the modality gap to increase gradually with time steps during inference, and (2) the modality gap has a long-tail problem, i.e., there are a few cases where the modality gap is very large. To solve these problems, we propose Cross-modal Regularization with Scheduled Sampling (CRESS), which simulates the decoding situation through scheduled sampling during training, and introduces cross-modal regularization loss to reduce the prediction difference between ST and MT, so that the predictions of the two tasks in the decoding stage are more consistent. Experimental results show that our method achieves significant improvement in all eight directions of the ST benchmark dataset MuST-C, reaching the current state-of-the-art performance.
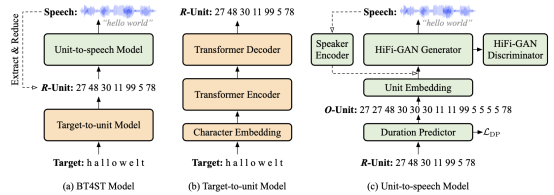
- Back Translation for Speech-to-text Translation Without Transcripts(Qingkai Fang, Yang Feng).
- Accepted by ACL 2023 Main Conference. Long Paper.
Abstract: Speech translation (ST) usually faces the challenge of data scarcity, and most of the existing approaches utilize additional automatic speech recognition (ASR) data or machine translation (MT) data during training to enhance the ST model. However, it is estimated that there are about 3000 languages in the world without corresponding transcribed text. For ST tasks from these languages to other languages, there is no ASR or MT data to exploit. In this paper, we aim to utilize the large-scale monolingual corpus of the target language to enhance ST in the absence of source transcripts. Inspired by the back translation (BT) approach in MT, we aim to design a back translation approach for ST that can synthesize a pseudo-ST corpus from the target monolingual corpus without relying on source transcripts. The generation from target text to source speech is challenging due to the generation from short sequences to long sequences and the existence of a one-to-many mapping between them. For this reason, we introduce discrete units as an intermediate representation. We first translate the target text to a sequence of discrete units corresponding to the source speech by a sequence-to-sequence model, and then convert it to the corresponding waveform by a vocoder. Experiments on the MuST-C dataset show that our method is able to synthesize high-quality pseudo-ST data from target monolingual data, significantly improving the performance of the baseline model.
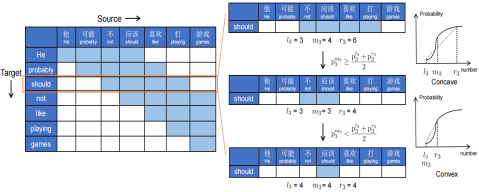
- Learning Optimal Policy for Simultaneous Machine Translationvia Binary Search(Shoutao Guo, Shaolei Zhang, Yang Feng).
- Accepted by ACL 2023 Main Conference. Long Paper.
Abstract: Simultaneous machine translation (SiMT) starts to output the generated translation before reading the whole source sentence and needs a precise policy to decide when to output the generated translation. However, there is no golden policy corresponding to parallel sentences as explicit supervision, which often leads to a lack of source information or the introduction of additional delays. In this paper, we propose the SiMT method based on binary search (BS-SiMT), which utilizes binary search to construct the optimal translation policy online and trains the SiMT model accordingly. Then the SiMT model can learn the optimal policy with explicit supervision and complete translation according to the learned policy during inference. Experiments on multiple translation tasks have shown that our method can exceed strong baselines under all latency and the learned policy is more accurate.
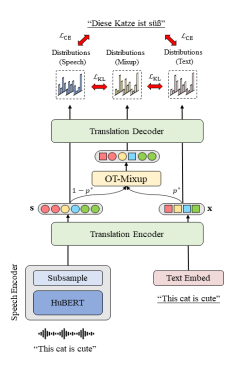
- CMOT: Cross-modal Mixup via Optimal Transport for Speech Translation(Yan Zhou, Qingkai Fang, Yang Feng).
- Accepted by ACL 2023 Main Conference. Long Paper.
Abstract: End-to-end speech translation (ST) is the task of translating speech signals in the source language into text in the target language. As a cross-modal task, end-to-end ST is difficult to train with limited data. Existing methods often try to transfer knowledge from machine translation (MT), but their performances are restricted by the modality gap between speech and text. In this paper, we propose Cross-modal Mixup via Optimal Transport (CMOT) to overcome the modality gap. We find the alignment between speech and text sequences via optimal transport, and then mix up the sequences from different modalities at a token level using the alignment. Experiments on MuST-C ST benchmark demonstrate that CMOT achieves an average BLEU of 30.0 in 8 translation directions, outperforming previous methods. Further analysis shows CMOT can adaptively find the alignment between modalities, which helps alleviate the modality gap between speech and text.
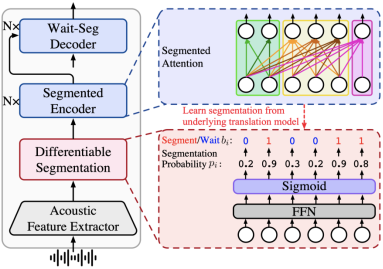
- End-to-End Simultaneous Speech Translation with Differentiable Segmentation(Shaolei Zhang, Yang Feng).
- Accepted by Findings of ACL 2023. Long Paper.
Abstract: End-to-end simultaneous translation (ST) outputs translation while receiving the streaming speech inputs, and hence needs to segment the speech inputs and then translate based on the current received speech. Segmenting at those unfavorable moments will break the acoustic integrity and further drop the performance of the translation model. Therefore, learning to segment the speech inputs at those moments that are beneficial for the translation model to produce high-quality translation is the key to ST. Existing ST methods, either using the fixed-length segmentation or external segmentation model, always separate segmentation from the underlying translation model, where the gap makes the segmentation results not necessarily beneficial to the translation. In this paper, we propose Differentiable Segmentation (DiSeg) for ST to directly learn segmentation from the underlying translation model. DiSeg turns hard segmentation into differentiable through the proposed expectation training, enabling it to be jointly trained with the translation model and thereby learn the translation-beneficial segmentation. Experiments on two ST benchmarks show that DiSeg outperforms strong baselines and achieves state-of-the-art performance.