Congratulations! NLP's 2 papers are accepted by ICLR 2023! The full name of ICLR 2023 is the 11th International Conference on Learning Representations. ICLR was founded by Yoshua Bengio and Yann LeCun, two of the three giants of deep learning, and has been held annually since 2013. It is one of the top conferences in the field of deep learning. ICLR is currently ranked 9th in Google Scholar's ranking of academic conferences/journals. ICLR 2023 will be held in Kigali, Rwanda from May 1 to May 5, 2023.

The accepted paper are summarized as follows:
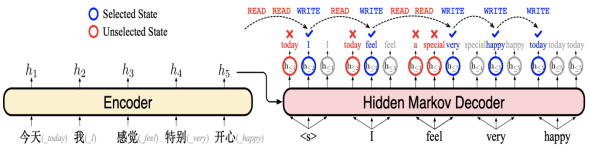
1. Title: Hidden Markov Transformer for Simultaneous Machine Translation
Authors: Shaolei Zhang, Yang Feng
Abstract: Simultaneous machine translation (SiMT) outputs the target sequence while receiving the source sequence, and hence learning when to start translating each target token is the core challenge for SiMT. However, it is non-trivial to learn the optimal moment among many possible moments of starting translating, as the moments of starting translating always hide inside the model and we can only supervise the SiMT model with the observed target sequence. In this paper, we propose Hidden Markov Transformer (HMT), which treats the moments of starting translating as hidden events and the target sequence as the corresponding observed events, thereby organizing them as a hidden Markov model. HMT explicitly models multiple moments of starting translating, used as the candidate hidden events, and then selects one to generate the target token. During training, by maximizing the marginal likelihood of the target sequence over multiple moments of starting translating, HMT learns to start translating at the moments that target tokens can be generated more accurately. Experiments on multiple SiMT benchmarks show that HMT outperforms strong baselines and achieves state-of-the-art performance.
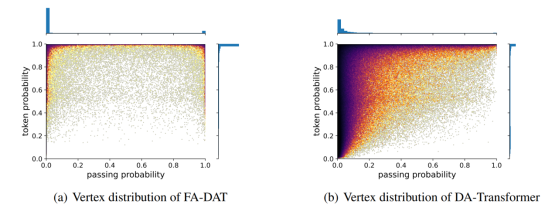
2. Title: Fuzzy Alignments in Directed Acyclic Graph for Non-autoregressive Machine Translation
Authors: Zhengrui Ma, Chenze Shao, Shangtong Gui, Min Zhang and Yang Feng
Abstract: Non-autoregressive translation (NAT) reduces the decoding latency but suffers from performance degradation due to the multi-modality problem. Recently, the structure of Directed Acyclic Graph has achieved great success in NAT, which tackles the multi-modality problem by introducing dependency between vertices. However, training it with Negative Log Likelihood loss implicitly requires a strict alignment between reference tokens and vertices, weakening its ability to handle multiple translation modalities. In this paper, we hold the view that all paths in the graph are fuzzily aligned with the reference sentence. We do not require the exact alignment but train the model to maximize a fuzzy alignment score between the graph and reference, which takes captured translations in all modalities into account. Extensive experiments on major WMT benchmarks show that our method substantially improves translation performance and increases prediction confidence, setting a new state of the art for NAT on the raw training data.