简介:为了解决NMT训练和测试时候context不一致的情况,我们从ground truth和自己生成的译文中以一定的概率采样词语作为context,随着训练的进行,选择ground truth词语的概率进行衰减,在RNNSearch和Transformer上翻译性能均有大幅提升。
motivation: 机器翻译的通常做法先encode再decode,decode过程每一个step吸收前一step的输出作为输入。因此会带来两个问题:
1. decode的过程如果是在train环节,每一个step在吸收上一step的输出时,吸收到的是ground truth word,而在inference环节,吸收到的是真正上一个step的预测结果,这并不能保证上一step的输出一定是正确的ground truth word. 这是train和inference环节的一个gap,带来的直接后果就是inference环节如果在某一个step预测错误,那么错误会一直影响下游其他step的预测。
2. 翻译问题可能存在有多种翻译方法,训练过程强行要求模型一字不变的往target方向靠拢loss计算和任务目标就是有偏的。如:
reference: We should comply with the rule.
candidate: We should abide by the rule.
approach: 从数据层面解决问题,即训练方式的改变,每一步喂给model的不能总是ground truth word。实际操作中,以p的概率喂给model ground truth word, 以1-p的概率选择上一步预测的word, 也就是oracle word,这么做就是为了缩小train过程和inference过程的差距。
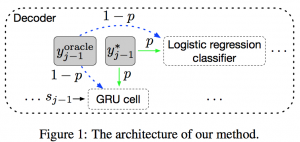
1. 对于问题1,比如要将序列abcdefg翻译成ABCDEFG,如果中间步骤翻译错了翻译成了ABCDXYZ,需要让model感知到,需要让loss计算中给更大的惩罚。而不是每一步都喂给model上一步的ground truth word, 否则翻译出来的结果成了ABCDXFG,loss的惩罚太小了。
2. 对于问题2,如果train过程允许有不同的正确翻译方式,那也就不会强行让model去把abide by 学成 abide with。
方法具体操作流程如下:
1. word-level oracle,取上一步的hidden state对每一个word直接进行多分类,选个概率大的作为上一步的输出。为了增强系统健壮性,增加了noise进行干扰。即使有干扰的情况下,也要求model能得出正确解。

2. Sentence-Level Oracle,先通过beam search的方法得到k个最佳翻译,在翻译过程中也会对每一步添加noise操作,最后取BLEU score最大的sentence作为sentence-level oracle。本质是想每一步不仅仅用ground truth word做输入,而是更多的翻译变种来输入。
Experimental results:
