2023年5月,课题组有5篇论文被ACL 2023录用,其中4篇论文被ACL主会录用,1篇被Findings of ACL录用。 ACL的全称是The Association for Computational Linguistics,是国际计算语言学界影响力最大的学术组织。ACL年度会议也是计算语言学领域的最重要的国际会议,是CCF推荐的计算语言学方面唯一的A类会议。ACL主会论文收录在Proceedings of ACL, Findings of ACL是从ACL 2021开始引入的在线附属出版物。ACL 2023将于2023年7月9日-7月14日在加拿大多伦多举行。
被录用论文简介如下:
- Understanding and Bridging the Modality Gap for Speech Translation (Qingkai Fang, Yang Feng).
- Accepted by ACL 2023 Main Conference.
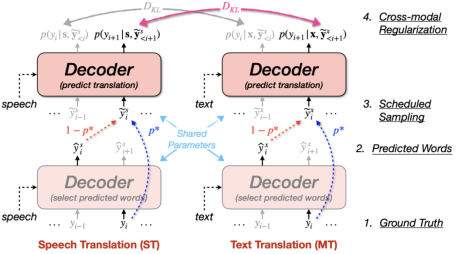
简介:语音翻译将输入语音直接翻译为另外一种语言的文字,有效减小了不同语言人群之间的沟通障碍。由于语音翻译语料稀缺,源语音到目标文本的映射学习难度较大,研究者们通常引入文本翻译任务来辅助语音翻译的训练。然而,由于语音与文本之间存在模态鸿沟,语音翻译的性能通常落后于文本翻译。在本文中,我们首先基于解码器的模态间表示差异来衡量模态鸿沟的显著程度,我们发现(1)机器翻译中的曝光偏差问题导致解码阶段模态鸿沟随时间步逐渐增大;(2)模态鸿沟存在长尾问题,即存在少数情况下模态鸿沟非常大。为了解决这两个问题,我们提出了基于计划采样的跨模态正则化方法(Cross-modal Regularization with Scheduled Sampling, CRESS),在训练时通过计划采样模拟解码的情形,并在此基础上引入跨模态正则项损失减小语音翻译与文本翻译的预测差异,从而使两个任务在解码阶段的预测更加一致。实验结果表明,该方法在语音翻译基准数据集MuST-C的所有8个语向上均取得了显著提升,达到了目前最先进的性能。
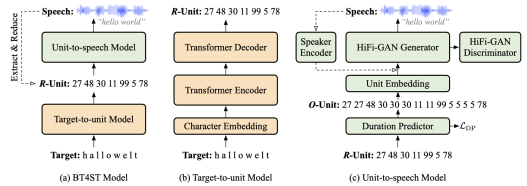
- Back Translation for Speech-to-text Translation Without Transcripts(Qingkai Fang, Yang Feng) .
- Accepted by ACL 2023 Main Conference.
简介:语音翻译通常面临数据稀缺的挑战,已有的方法大多在训练时利用额外的语音识别数据或机器翻译数据来增强语音翻译模型。然而,据统计,世界上存在约3000种语言没有对应的转写文本。对于从这些语言到其他语言的语音翻译任务,没有语音识别或机器翻译的数据可以利用。在本文中,我们旨在利用目标语言的大规模单语语料来增强源语言没有转写文本情况下的语音翻译。受到机器翻译中反向翻译(Back Translation)方法的启发,我们希望为语音翻译设计一种反向翻译方法,能够在不依赖源语言转写文本的情况下,从目标语言的单语语料合成语音翻译的伪平行语料。由于目标文本到源语音的生成是从短序列到长序列的生成,且二者之间存在一对多的映射,使该生成过程极具挑战性。为此,我们引入离散单元作为中间表示,首先通过一个序列到序列模型将目标文本翻译到源语音对应的离散单元序列,再通过一个声码器将其转化为对应的声波。在MuST-C数据集三个语向上的实验表明,该方法能够从目标语言单语数据合成高质量的伪数据,显著提升基线模型的性能。
- Learning Optimal Policy for Simultaneous Machine Translationvia Binary Search(Shoutao Guo, Shaolei Zhang, Yang Feng).
- Accepted by ACL 2023 Main Conference.
简介:同步机器翻译(Simultaneous Machine Translation,SiMT)在输入整个源端句子之前便开始输出生成的翻译,因而需要一个精确的策略决定模型何时输出翻译。然而,现有的平行训练语料中缺少精准策略作为策略学习的显式监督信号,这往往导致缺少源端信息或是引入额外延时。在本文中,我们提出了基于二分搜索的SiMT方法(BS-SiMT),它基于二分搜索在线构建最优翻译策略,同时据此训练翻译模型。随后,SiMT模型将以显式监督的方式学习最优策略,并在推理时依据学习到的策略输出翻译。多个翻译任务的实验表明我们的方法可以在所有延时下达到较好效果,策略更加准确。

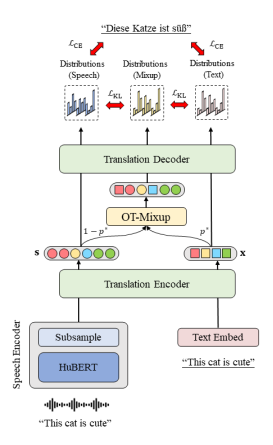
- CMOT: Cross-modal Mixup via Optimal Transport for Speech Translation(Yan Zhou, Qingkai Fang, Yang Feng).
-
Accepted by ACL 2023 Main Conference.简介:端到端语音翻译是将源语言的语音信号翻译成目标语言的文本的任务。端到端语音翻译作为一项跨模态任务,在数据有限的情况下很难进行训练。现有的方法通常试图从机器翻译任务中进行知识迁移,但它们的性能受语音和文本间模态鸿沟的限制。在本文中,我们提出了基于最优传输的跨模态混合(CMOT)方法,以克服模态鸿沟。我们通过最优传输找到语音和文本序列之间的对齐,然后使用该对齐在标识符级别上混合不同模态的序列。在 MuST-C 语音翻译数据集上的实验表明,CMOT 在8个翻译方向上达到了30.0的平均 BLEU 值,优于先前的方法。进一步的分析表明,CMOT 可以自适应地找到模态之间的对齐关系,这有助于缓解语音和文本之间的模态鸿沟。
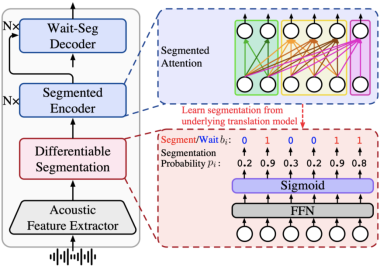
- End-to-End Simultaneous Speech Translation with Differentiable Segmentation(Shaolei Zhang, Yang Feng).
- Accepted by Findings of ACL 2023.
简介:端到端实时语音翻译(ST)在接收流式语音输入的同时输出翻译,因此需要对语音输入进行分割,然后根据当前接收到的语音进行翻译。在那些不利时刻进行分段会破坏声学完整性并进一步降低翻译模型的性能。因此,学习在那些有利于翻译模型产生高质量翻译的时刻对语音输入进行分割是ST的关键。现有的ST方法,无论是使用固定长度的分割还是外部分割模型,总是将分割与底层翻译模型分开,其中的鸿沟难以保证分割结果对翻译有利。在本文中,我们为ST提出了可微分割 (Differentiable Segmentation, DiSeg)。DiSeg通过期望训练直接从底层翻译模型中学习语音分割,并且能同时处理离线和实时场景下的语音翻译。实验表明,DiSeg取得了最先进的实时语音翻译性能,在滞后2s的延时下达到了离线翻译性能。