2022年10月,课题组有8篇论文被EMNLP 2022录用,其中4篇主会论文,4篇Findings论文。EMNLP的全称是Conference on Empirical Methods in Natural Language Processing,由国际计算语言学会ACL旗下SIGDAT组织,每年举办一次,为自然语言处理领域最具影响力的国际会议之一。
被录用论文简介如下:
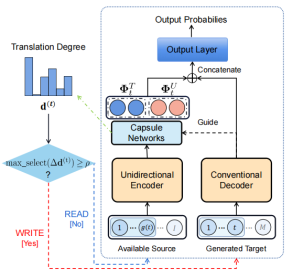
- Counterfactual Data Augmentation via Perspective Transition for Open-Domain Dialogues (Jiao Ou, Jinchao Zhang, Yang Feng, Jie Zhou).
- Accepted by Main Conference.
简介:构建开放领域的对话系统需要高质量的对话数据集,人类对话在给定的对话历史下可以有不同的回复,这些回复甚至是语义迥异的,因此,对话数据中只有包含针对同一对话历史的多样性回复才更符合人类对话的特点,然而收集这样的高质量对话数据是耗时耗力的。为了避免人工收集语料,我们提出了一种数据增强方法,通过反事实推理生成模型自动生成具有不同语义的高质量回复。具体来说,给定一个对话回复,反事实推理生成模型首先根据对话历史确定可行的回复角度,然后基于选择的角度来生成具体的回复。选择多个不同的回复角度,就可以得到许多语义迥异的回复。于是对话历史和生成的回复便构成了新的对话。实验结果表明,我们的数据增强方法可以为给定的对话历史增强具有不同语义的高质量回复,并且可以在多个下游任务上超过基线方法。
- Continual Learning of Neural Machine Translation within Low Forgetting Risk Regions (Shuhao Gu, Bojie Hu, Yang Feng).
- Accepted by Main Conference.
简介:本文在无需访问以前的训练数据或引入模型分离的情况下进行大规模预训练神经机器翻译模型的连续学习。我们认为,广泛使用的基于正则化的方法在执行多目标学习时会产生辅助损失,因此会出现错误估计问题,并且不能始终在以前的任务和新任务之间取得良好的平衡。为了解决这个问题,我们提出了一种基于真实误差局部特征的两阶段训练方法。为了避免灾难性遗忘问题,我们首先搜索遗忘风险较低的区域,在该区域中,随着参数的更新,模型可以保持先前任务的性能。然后,我们可以仅使用新的训练数据在该区域内持续训练模型,以适应新任务。具体来说,我们提出了两种搜索低遗忘风险区域的方法,分别基于损失曲率和参数对模型输出的影响。我们对领域适应和更具挑战性的语言适应任务进行了实验,实验结果表明,与几个强基线系统相比,我们的方法可以取得显著的改进。

- Information-Transport-based Policy for Simultaneous Translation (Shaolei Zhang, Yang Feng).
- Accepted by Main Conference.
简介:同声传译 (ST) 在接收源输入的同时输出翻译,因此需要一个同传策略来确定是翻译目标词还是等待下一个源词。同声传译的主要挑战是每个目标词只能基于当前接收到的源词进行翻译,接收到的源信息将直接影响翻译质量。自然地,当前目标词的翻译接收到多少源信息应该是同传策略决定是翻译还是等待的关键证据。在本文中,我们将翻译过程视为从源到目标的信息运输,因此提出了基于信息运输(information transport)的同声传译策略(ITST)。 ITST对每个源词到当前目标词运输的信息权重进行量化,然后根据目标词累积接收到的源信息决定是否开始翻译。多个同声传译基准上的实验表明,ITST 在所有延迟下都优于强基线并实现了最先进的性能。
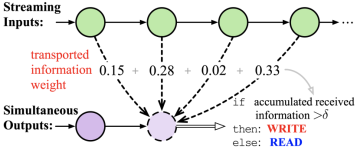
- Low-resource Neural Machine Translation with Cross-modal Alignment (Zhe Yang, Qingkai Fang, Yang Feng).
- Accepted by Main Conference.
简介:在低资源机器翻译任务中,现有的技术通常依赖于大规模的单语语料库,这对于一些低资源语言来说是不可行的。在本文中,我们通过引入视觉模态信息将几种低资源语言连接到一种特定的高资源语言上。具体来说,我们提出了一种跨模态对比学习方法来学习所有语言的公共空间。其中,我们进一步提出了粗糙的句子级对比学习方法和细粒度的词级别对比学习方法。实验结果和进一步的分析表明,我们的方法可以有效地学习跨模态和跨语言对齐,并且在zero-shot和few-shot场景下均取得了显著提升。
- Improving Zero-Shot Multilingual Translation with Universal Representations and Cross-Mappings (Shuhao Gu, Yang Feng).
- Accepted by Findings of EMNLP.
简介:在这个工作中,我们通过建模语言共享语义空间和统一映射关系来提升多语言翻译模型的零射翻译效果。基于最优运输理论,我们提出状态转移距离来减小不同语言语义空间的差距;基于一致性预测,我们帮助不同语言学习统一映射关系。实验表明该方法能大幅提高多语言零射翻译性能。
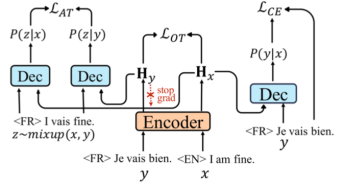
- Viterbi Decoding of Directed Acyclic Transformer for Non-Autoregressive Machine Translation (Chenze Shao, Zhengrui Ma, Yang Feng).
- Accepted by Findings of EMNLP.
简介:非自回归机器翻译模型能进行并行解码,但也因此缺乏对序列依赖关系的建模能力。基于有向无环图的非自回归模型能在图中建模序列依赖,这使它无需知识蒸馏就能达到与自回归模型相似的性能,但也导致它需要在解码时进行顺序决策,无法保证生成全局最优的译文。对此,我们为有向无环图模型建立了基于维特比算法的解码框架,能够在任意译文长度限制下找出使翻译路径与译文概率最大的联合最优解,并且模型能通过长度惩罚项灵活控制译文长度。实验结果表明,我们的方法能稳定地提升模型的翻译性能,并且几乎不会对解码速度造成影响。
- Wait-info Policy: Balancing Source and Target at Information Level for Simultaneous Machine Translation (Shaolei Zhang, Shoutao Guo, Yang Feng).
- Accepted by Findings of EMNLP.
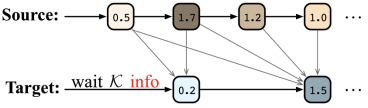
简介:同步机器翻译(SiMT)在接收源输入的同时输出翻译,因此需要平衡接收到的源信息和翻译的目标信息,以在等待输入或输出翻译之间做出合理的决定。以前的方法总是在令牌级别平衡源和目标信息,要么直接等待固定数量的令牌,要么根据当前令牌调整等待。本文中,我们提出了一个wait-info policy来在信息级别平衡源和目标。我们首先量化每个令牌中包含的信息量,命名为 info。然后在同步机器翻译过程中,根据先前目标输出的总信息与接收到的源输入之间的比较结果做出等待或输出的决定。实验表明,我们的方法在所有延迟下都优于强基线,并通过提出的info在源和目标之间实现了更好的平衡。
- Turning Fixed to Adaptive: Integrating Post-Evaluation into Simultaneous Machine Translation (Shoutao Guo, Shaolei Zhang, Yang Feng).
- Accepted by Findings of EMNLP.
简介:同声传译在读入整个源端句子前便开始翻译,采用固定策略或是自适应策略来获取更优的延时和翻译质量间的权衡。之前的方法过度依赖于读写操作的决策模块,决定写操作后立即写出当前生成的单词,但这将不可避免地导致错误动作的发生。本文将合理性评估引入读写策略,其在执行动作前利用源端信息的改变来评估读写动作的合理性,据此再执行相应的动作,从而减少了不合理的操作,获得了更优的关于翻译质量和延时之间的权衡。