课题组今年有7篇论文被ACL 2022接收, 其中6篇论文被ACL主会录用,1篇被findings of ACL录用。ACL全称是The 60th Annual Meeting of the Association for Computational Linguistics,是自然语言处理领域国际顶级会议之一;Findings of ACL是ACL 2021引入的在线附属出版物。
Overcoming Catastrophic Forgetting beyond Continual Learning: Balanced Training for Neural Machine Translation(Chenze Shao, Yang Feng)
ACL, long paper
神经网络模型在新数据集上训练时,通常会逐渐遗忘旧数据集上学到的知识,在持续学习中的这种现象被称为灾难性遗忘。然而,我们发现即使模型始终在同一数据集上训练,灾难性遗忘现象仍然存在,具体表现为模型对新接触的样本关注更多、对较早接触的样本关注更少,我们把这种在训练样本上的不均衡问题称为“非均衡训练”。通过实验验证,我们发现非均衡训练问题在神经网络模型广泛存在,在机器翻译任务上尤其严重。通过进一步分析,我们揭示了在机器翻译上广泛使用的检查点平均技术与非均衡训练问题的联系,并确认了非均衡训练问题会对模型性能造成影响。为缓解这一问题,我们提出了互补在线知识蒸馏技术,通过对数据集的互补切分来保证教师模型始终与学生模型互补,从而使模型能够均匀地从所有训练样本中学习。在多个机器翻译任务上的实验表明,我们的方法成功地缓解了非均衡训练问题,取得了显著的性能提升。
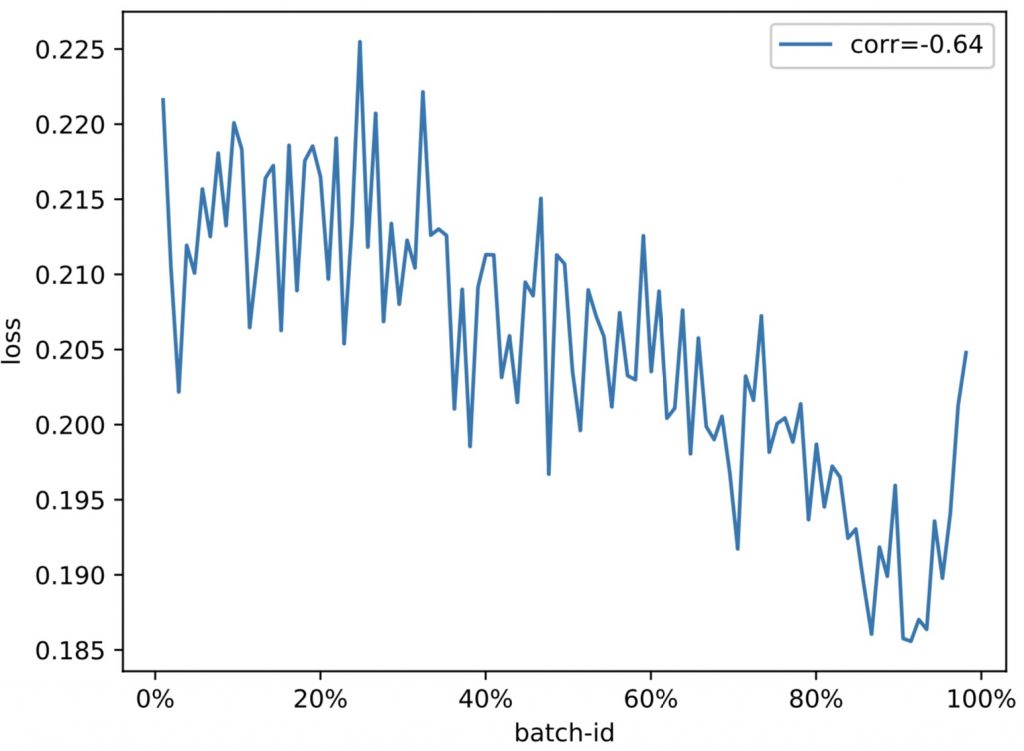
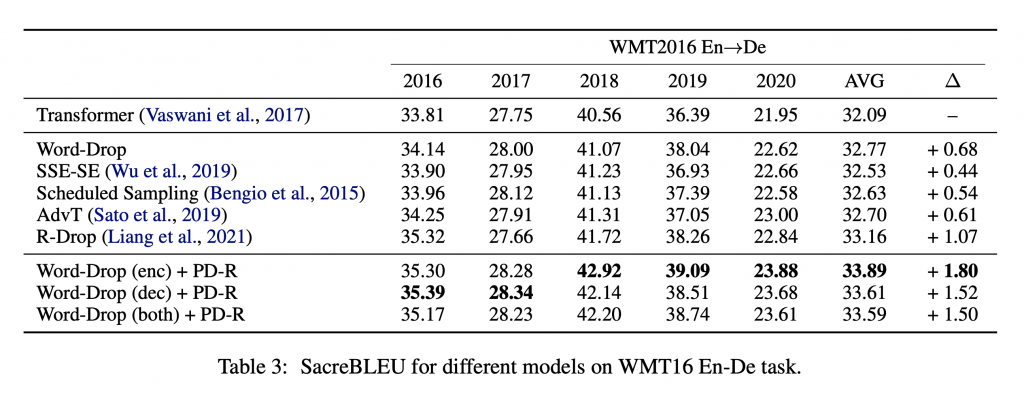
Prediction Difference Regularization against Perturbation for Neural Machine Translation (Dengji Guo, Zhengrui Ma, Yang Feng, Min Zhang)
ACL, long paper
已有工作表明,训练时在输入中添加噪声能够提升神经网络机器翻译模型的泛化能力。本文认为这种方法片面强调了模型对训练数据的过拟合,对噪声数据进行了无差别拟合,却忽视了模型对训练数据的欠拟合。利用模型在噪声输入和原始输入上的预测差异,本文分析了模型对词级别样本的过拟合和欠拟合现象,揭示了模型的欠拟合现象,并实验证明了已有方法的缺陷。最后,本文提出将预测差异作为正则项,同时约束模型对过拟合和欠拟合行为。该方法在WMT16英德翻译任务上取得了1.80 SacreBLEU的提升。
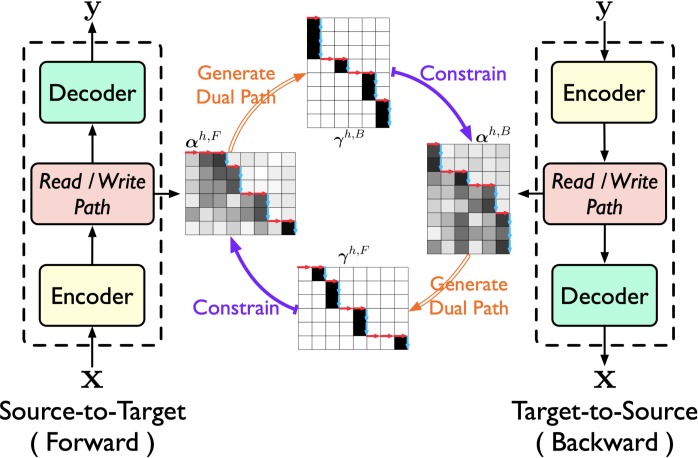
Modeling Dual Read/Write Paths for Simultaneous Machine Translation(Shaolei Zhang, Yang Feng)
ACL, long paper
同步机器翻译在阅读源语句时输出翻译,因此需要模型在翻译过程中确定是等待下一个源词(READ)还是生成目标词(WRITE),这些动作构成了读/写路径。由于缺乏明确的约束,读/写路径一直是同步机器翻译性能的瓶颈。在本文中,我们开发了对偶路径同传(Dual Paths SiMT)来约束读/写路径,从而实现更好的性能。由于两个翻译方向上的读/写路径之间的对偶形式,我们明确地利用它们之间的对偶约束来相互约束。具体来说,‘Dual Paths’由源到目标(source-to-target)模型和目标到源(target-to-source)模型组成,它们具有自己的读/写路径。两个模型在对偶约束下联合优化了各自的读/写路径。在 En-Vi和De-En上的实验表明,我们的方法在两个方向上都提高了同步机器翻译性能,并且优于强基线。
Reducing Position Bias in Simultaneous Machine Translation with Length-Aware Framework(Shaolei Zhang, Yang Feng)
ACL, long paper
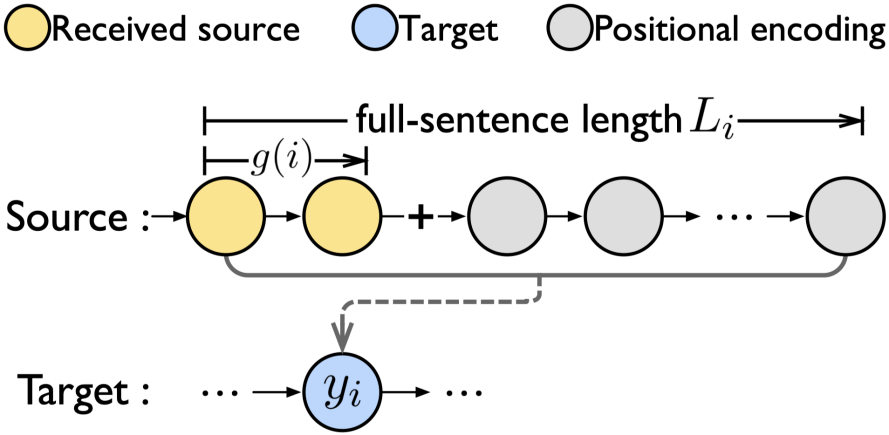
同步机器翻译 (SiMT) 在接收流式源输入时开始翻译,因此在翻译过程中源语句总是不完整的。与使用传统 seq-to-seq 架构的 整句翻译不同,同步机器翻译经常采用 prefix-to-prefix 架构,强制每个目标词只与部分源前缀对齐,以适应流输入中不完整的源。然而,因为总是出现在更多的前缀中,在前面位置的源词往往被虚幻地认为更重要。这会导致位置偏差,使得模型在测试中往往更加关注前面的源位置。在本文中,我们首先分析了同步机器翻译中的位置偏差现象(position bias),并开发了一个长度感知框架,通过弥补同步机器翻译和整句翻译之间的结构差距来减少位置偏差。具体来说,给定流输入,我们首先预测全句长度,然后用位置编码填充未来的源位置,从而将流输入变成伪全句。所提出的框架可以集成到大多数现有的方法中,以进一步提高性能。对两种具有代表性的同步机器翻译方法的实验表明,我们的方法成功地减少了位置偏差以实现更好的性能。
Gaussian Multi-head Attention for Simultaneous Machine Translation(Shaolei Zhang, Yang Feng)
Findings of ACL, long paper
同步机器翻译 (SiMT) 在接收流式源输入的同时输出翻译,因此需要一个策略来确定从哪里开始翻译。目标词和源词之间的对齐通常揭示了对每个目标词的信息量最大的源词,因此桥接了翻译质量和延迟,但不幸的是,现有的方法没有明确地对对齐进行建模以建模这种关系。在本文中,我们提出了高斯多头注意力(Gaussian Multihead Attention, GMA),通过以统一的方式对对齐和平移进行建模来开发新的同步机器翻译策略。对于读/写策略,GMA 对每个目标词的对齐源位置进行建模,并相应地等待至其对齐位置开始翻译。为了将对齐学习整合到翻译模型中,引入了以预测对齐位置为中心的高斯分布作为对齐相关的先验,它与翻译相关的软注意力合作确定最终的注意力。在En-Vi 和De-En任务的实验表明,我们的方法在翻译和延迟之间的权衡上优于强基线。

Neural Machine Translation with Phrase-Level Universal Visual Representations (Qingkai Fang, Yang Feng)
ACL, long paper
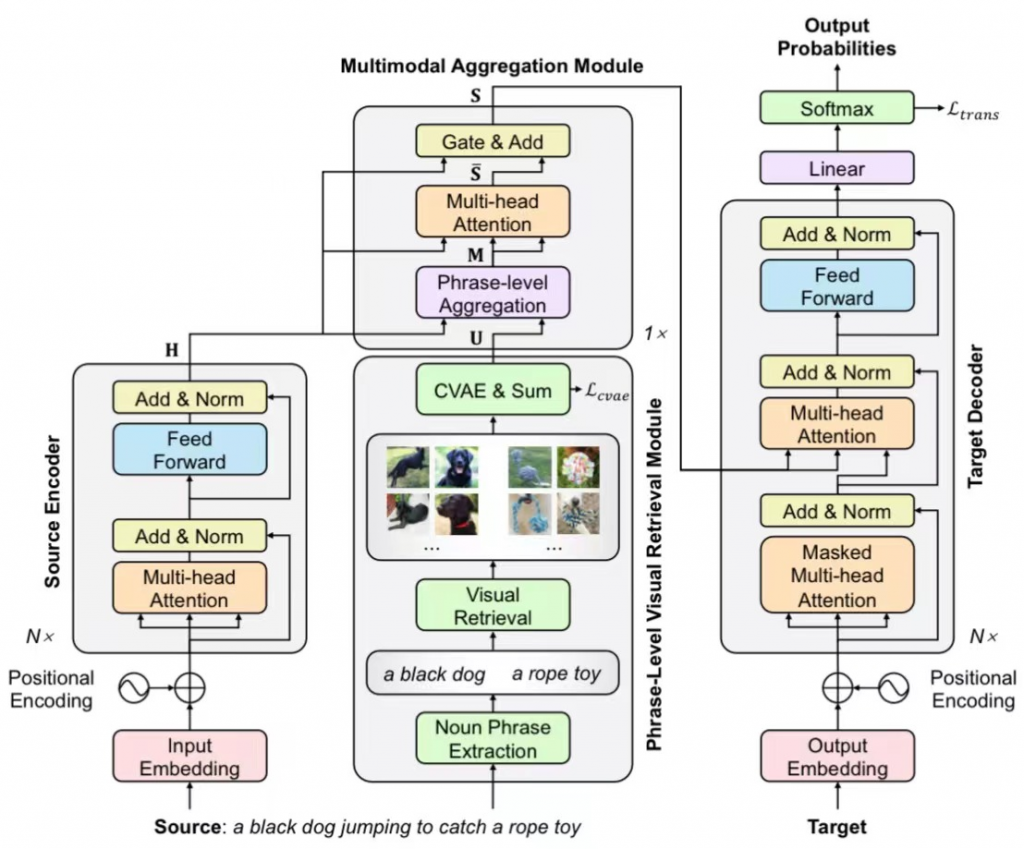
多模态机器翻译旨在借助图像信息辅助机器翻译,近年来受到广泛关注。然而,已有的大多数方法需要成对的句子和图片作为输入,这为多模态机器翻译的应用带来了较强的约束。为了打破这一约束,部分工作提出了基于检索的多模态机器翻译方法,即对于输入句子,从外部图片库中检索若干图片作为辅助。然而,我们发现句子级检索存在稀疏性,导致检索到的图片与输入句子相关性较差。为此,我们提出了短语级图像检索,为输入句子中的每个短语检索若干图像区域。此外,考虑到图片中包含的信息较为冗杂(如颜色、纹理、背景等),我们引入了一个条件变分自编码器模型来显式建模语义相关的图像特征。实验结果表明我们的方法在Multi30K En-De、En-Fr上均取得了显著的提升。
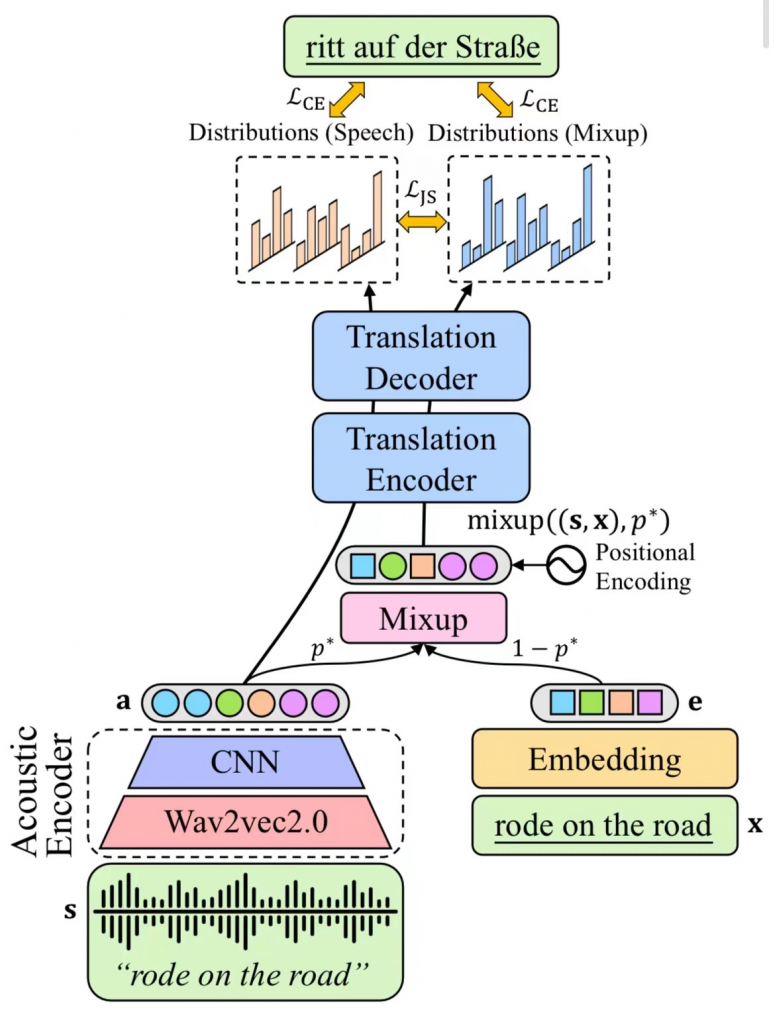
STMM: Self-learning with Speech-text Manifold Mixup for Speech Translation (Qingkai Fang, Rong Ye, Lei Li, Yang Feng, Mingxuan Wang)
ACL, long paper
端到端语音翻译的目标是利用一个模型完成从源语言语音到目标语言文本的翻译。由于语音翻译存在数据稀缺、任务复杂的挑战,以往工作通常会利用预训练、知识蒸馏等技术,借助额外的大规模文本翻译数据来辅助训练。然而,我们认为上述方法仍然没有充分利用已有的文本翻译数据,因为他们忽视了语音和文本间的模态鸿沟,即不同模态数据在连续空间中的表示存在较大差异。为了克服该问题,我们提出了一种基于Mixup的方法,对语音和文本序列进行单词级混合,从而得到跨模态的序列。在此基础上,我们引入了一个自我学习框架,将语音序列和跨模态序列一起输入模型,并使用JS散度拉近二者的输出。实验结果表明我们的方法在MuST-C数据集的8个语向上均取得了显著的提升,分析结果表明我们的方法能够有效减少跨模态表示差异。