2021年8月,课题组有1篇论文被CL录用。CL全称是Computational Linguistics,是国际计算语言学领域的顶级学术期刊,侧重模型算法和重大的理论问题。CL期刊每期录用4篇论文和2篇书评,一年共4期。自1988年创刊以来,国内单位共中稿10余篇。
Sequence-Level Training for Non-Autoregressive Neural Machine Translation (Chenze Shao, Yang Feng, Jinchao Zhang, Fandong Meng, Jie Zhou)
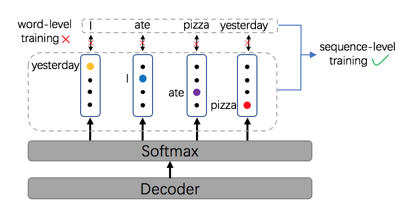
非自回归翻译模型在翻译速度上相比自回归模型有巨大优势,但缺乏合适的训练方法,因此性能落后于自回归模型。非自回归翻译通常以词级别的交叉熵损失为训练目标。交叉熵损失要求模型输出与参考译文逐词严格对齐,不允许模型输出发生任何偏移。然而,由于语言有丰富多样的变化,严格对齐在实际上很少出现,因此交叉熵损失难以正确评估模型输出的好坏。本文探索了对非自回归模型的序列级训练方法,从序列整体上评估模型的输出。首先,我们采用传统的强化学习方法来训练模型优化序列级的奖赏,并利用非自回归生成的特性提出几种针对性的方法来减小梯度估计的方差。更进一步,我们提出了一种基于n元组的可微训练目标,可以在不做任何近似下直接最小化输出与参考译文的差异。最后,我们用一种三阶段训练策略来结合上面的训练方法,在各个数据集上都取得了显著的提升,大幅缩小了非自回归模型与自回归模型之间的性能差距。