9 papers from NLP group accepted by ACL 2024
In May 2024, 9 papers from the Natural Language Processing Group were accepted by the ACL 2024 conference, of which 4 papers were accepted by the ACL main committee and 5 papers were accepted by Findings of ACL. The full name of ACL is The Association for Computational Linguistics, which is the most influential academic organization in the international field of computational linguistics. The ACL Annual Conference is also the most important international conference in the field of computational linguistics, and is the only A-class conference recommended by CCF in the field of computational linguistics. Findings of ACL is an online supplementary publication introduced since ACL 2021.
A brief introduction to the accepted paper is as follows:
- - A Non-autoregressive Generation Framework for Simultaneous Speech-to-x Translation (Zhengrui Ma, Qingkai Fang, Shaolei Zhang, Shoutao Guo, Yang Feng, Min Zhang)
- Accepted by ACL 2024 Main Conference
Abstract: Simultaneous machine translation (SimulMT) models play a crucial role in facilitating speech communication. However, existing research primarily focuses on text-to-text or speech-to-text models, necessitating additional cascaded components to achieve speech-to-speech translation. These pipeline methods suffer from error propagation and accumulate delays in each cascade component, resulting in reduced synchronization between the speaker and listener. To overcome these challenges, we propose a novel non-autoregressive generation framework for simultaneous speech translation (NAST-S2$x$), which integrates speech-to-text and speech-to-speech tasks into a unified end-to-end framework. Drawing inspiration from the concept of segment-to-segment generation, we develop a non-autoregressive decoder capable of concurrently generating multiple text or acoustic unit tokens upon receiving each speech segment. The decoder can generate blank or repeated tokens and employ CTC decoding to dynamically adjust its latency. Experimental results on diverse benchmarks demonstrate that NAST-S2$x$ surpasses state-of-the-art models in both speech-to-text and speech-to-speech SimulMT tasks.
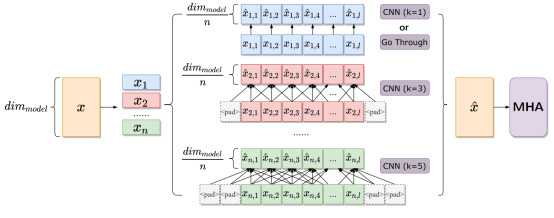
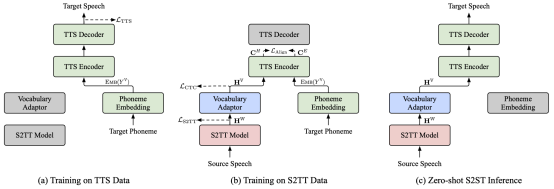
- - Can We Achieve High-quality Direct Speech-to-Speech Translation Without Parallel Speech Data? (Qingkai Fang, Shaolei Zhang, Zhengrui Ma, Min Zhang, Yang Feng)
- Accepted by ACL 2024 Main Conference
Abstract: Speech to Speech Translation (S2ST) refers to the highly challenging task of translating speech from the source language to the target language. The recently proposed Two pass S2ST model (such as UnitY, Translatotron 2, DASpeech, etc.) decomposes S2ST tasks into Speech to Text Translation (S2TT) and Text to Speech (TTS) within an end-to-end framework, and its performance surpasses traditional cascading models. However, model training still relies on parallel speech data, which is very difficult to collect. Meanwhile, due to the inconsistent lexical granularity of S2TT and TTS models, the models fail to fully utilize existing data and pre trained models. To address these challenges, this article first proposes a combined S2ST model called ComSpeech, which can seamlessly integrate any S2TT and TTS model into one S2ST model through a CTC based vocabulary adapter. In addition, this article proposes a training method that only uses S2TT and TTS data, which achieves zero sample end-to-end S2ST by using contrastive learning for representation alignment in the representation space, thereby eliminating the need for parallel speech data. The experimental results show that on the CVSS dataset, when trained with parallel speech data, ComSpeech outperforms the previous Two pass model in terms of translation quality and decoding speed. When there is no parallel speech data, ComSpeech ZS based on zero sample learning is only 0.7 ASR-BLEU lower than ComSpeech and is superior to cascaded models.
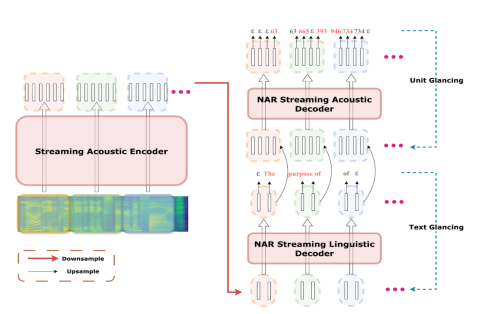
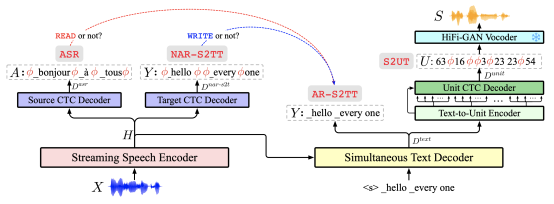
- - StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning (Shaolei Zhang, Qingkai Fang, Shoutao Guo, Zhengrui Ma, Min Zhang, Yang Feng)
- Accepted by ACL 2024 Main Conference
Abstract: Simultaneous speech-to-speech translation (Simul-S2ST) outputs target speech while receiving streaming speech inputs, which is critical for real-time communication. Beyond accomplishing translation between speech, SimulS2ST requires a policy to control the model to generate corresponding target speech at the opportune moment within speech inputs, thereby posing a double challenge of translation and policy. In this paper, we propose StreamSpeech, a direct Simul-S2ST model that jointly learns translation and simultaneous policy in a unified framework of multi-task learning. By leveraging multi-task learning across speech recognition, speech-to-text translation, and speech synthesis, StreamSpeech effectively identifies the opportune moment to start translating and subsequently generates the corresponding target speech. Experimental results demonstrate that StreamSpeech achieves state-of-the-art performance in both offline S2ST and Simul-S2ST tasks. Owing to the multitask learning, StreamSpeech is able to present intermediate results (i.e., ASR or translation results) during simultaneous translation process, offering a more comprehensive translation experience。
- - TruthX: Alleviating Hallucinations by Editing Large Language Models in Truthful Space (Shaolei Zhang, Tian Yu, Yang Feng)
- Accepted by ACL 2024 Main Conference
Abstract: Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks. However, they sometimes suffer from producing hallucinations, particularly in cases where they may generate untruthful responses despite possessing the correct knowledge. In this paper, we propose TruthX, an inference time method to elicit the truthfulness of LLMs by editing their internal representations in truthful space. TruthX employs an auto-encoder to map LLM’s representations into semantic and truthful latent spaces respectively, and applies contrastive learning to identify a truthful editing direction within the truthful space. During inference, by editing LLM’s internal representations in truthful space, TruthX effectively enhances the truthfulness of LLMs. Experiments show that TruthX effectively improves the truthfulness of 13 advanced LLMs by an average of 20% on TruthfulQA benchmark. Further analyses suggest that the truthful space acquired by TruthX plays a pivotal role in controlling LLM to produce truthful or hallucinatory responses.

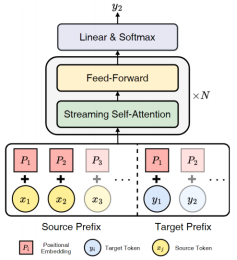
- - Decoder-only Streaming Transformer for Simultaneous Translation (Shoutao Guo, Shaolei Zhang, Yang Feng)
- Accepted by ACL 2024 Main Conference
Abstract: Simultaneous interpretation generates a translation while reading the source sentence, and generates a target prefix based on the source prefix. It utilizes the relationship between the source prefix and the target prefix to develop strategies for reading or generating words. The existing simultaneous interpreting methods mainly use the Encoder Decoder architecture. We have explored the potential of the Decoder Only architecture in simultaneous interpreting, because the Decoder Only architecture performs well in other tasks and has inherent compatibility with simultaneous interpreting. However, directly applying the Decoder Only architecture to simultaneous interpreting poses challenges in both training and reasoning. To this end, we propose the first Decoder Only simultaneous interpreting model, called Decoder only Streaming Transformer (DST). Specifically, DST encodes the positional information of the source language and target language prefixes separately, ensuring that the positional information of the target language prefix is not affected by the extension of the source language prefix. In addition, we propose a Streaming Self Attention (SSA) mechanism for the Decoder Only architecture. It can obtain translation strategies by evaluating the adequacy of input source information and combine it with soft attention mechanisms to generate translations. The experiment shows that our method has achieved the latest performance level in three translation tasks.
- - CTC-based Non-autoregressive Textless Speech-to-Speech Translation (Qingkai Fang, Zhengrui Ma, Yan Zhou, Min Zhang, Yang Feng)
- Accepted by Findings of ACL
Abstract: Direct Speech to Speech Translation has achieved significant results in translation quality, but due to the long length of speech sequences, it often faces the challenge of slow decoding speed. Recently, some studies have shifted towards non autoregressive (NAR) models to accelerate decoding speed, but their translation quality often lags significantly behind autoregressive (AR) models. This article investigates the performance of a Connected Temporal Classification (CTC) based NAR model in speech to speech translation tasks. The experimental results show that by combining pre training, knowledge distillation, and advanced NAR training techniques such as Glancing training and non monotonic alignment, the CTC based NAR model can match the AR model in translation quality and achieve a decoding speed improvement of up to 26.81 times.
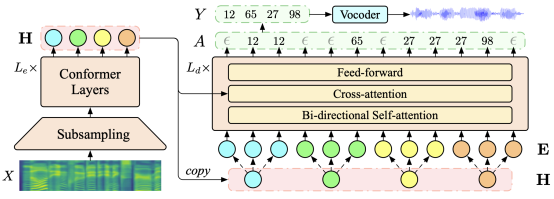
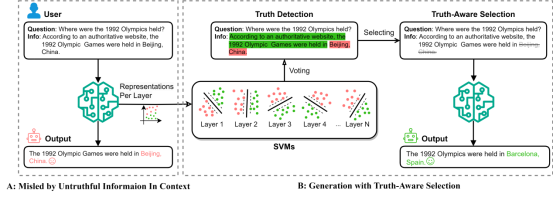
- - Truth-Aware Context Selection: Mitigating the Hallucinations of Large Language Models Being Misled by Untruthful Contexts. (Tian Yu, Shaolei Zhang, Yang Feng)
- Accepted by Findings of ACL
Abstract: Although large language models (LLMs) have demonstrated impressive text generation capabilities, they are easily misled by the untruthful context provided by users or knowledge augmentation tools, thereby producing hallucinations. To alleviate the LLMs from being misled by untruthful information and take advantage of knowledge augmentation, we propose Truth-Aware Context Selection (TACS), a lightweight method to shield untruthful context from the inputs. TACS begins by performing truth detection on the input context, leveraging the parameterized knowledge within the LLM. Subsequently, it constructs a corresponding attention mask based on the truthfulness of each position, selecting the truthful context and discarding the untruthful context. Additionally, we introduce a new evaluation metric, Disturbance Adaption Rate, to further study the LLMs' ability to accept truthful information and resist untruthful information. Experimental results show that TACS can effectively filter information in context and significantly improve the overall quality of LLMs' responses when presented with misleading information.
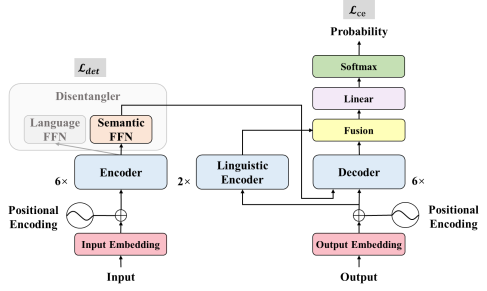
- - Improving Multilingual Neural Machine Translation by Utilizing Semantic and Linguistic Features. (Mengyu Bu, Shuhao Gu, Yang Feng).
- Accepted by Findings of ACL
Abstract: Multilingual neural machine translation can be seen as the process of combining the semantic features of the source sentence with the language features of the target sentence. Based on this, we propose to enhance the zero shot translation ability of multilingual translation models by utilizing the semantic and linguistic features of multiple languages. On the encoder side, we introduce a decoupling learning task that aligns the encoder representation by decoupling semantic and language features, thereby achieving lossless knowledge transfer. On the decoder side, we use a language encoder to integrate low-level language features to assist in generating the target language. The experimental results show that compared with the baseline system, our method can significantly improve zero shot translation while maintaining the performance of supervised translation.
- - Integrating Multi-scale Contextualized Information for Byte-based Neural Machine Translation. (Langlin Huang, Yang Feng)
- Accepted by Findings of ACL
Abstract: The machine translation model based on byte encoding alleviates the problems of sparse word lists and imbalanced word frequencies in multilingual translation models, but it has the disadvantage of low byte sequence information density. An effective solution is to use local contextualization, but existing work cannot select an appropriate local scope of action based on input. This article proposes a Multi Scale Attention method that applies local contextualization with different scopes of action to different hidden state dimensions, and dynamically integrates multi granularity semantic information through an attention mechanism, achieving dynamic integration of multi granularity information. Experimental results have shown that our method outperforms existing works in multilingual scenarios and far surpasses subword based translation models in low resource scenarios.